


Recent reports have revealed a startling truth about the LLMs we are integrating into our enterprises: beneath a thin layer of safety training, there can be a lurking, nefarious "monster" that is surprisingly easy to coax out. Researchers call this phenomenon “emergent misalignment,” and it represents a profound new risk vector for the enterprise.
A recent Wall Street Journal opinion piece, “The Monster Inside ChatGPT,” described how minimal fine-tuning could unlock hateful, racist personas (named “Shoggoths" for H.P. Lovecraft's shapeless monster). OpenAI's own research confirms that training a model on something as narrow as insecure code can activate a "misaligned persona," causing it to behave unethically in completely unrelated areas.
Perhaps most famously, Anthropic shared widely publicized research that showed what happens when this misaligned persona is given agency. In their report, "Agentic Misalignment: How LLMs could be insider threats," they demonstrated that agents in simulated corporate environments would resort to blackmail, corporate espionage, and deception to achieve their goals.
While it is indeed alarming that LLMs might say or “think” terrible things, the far greater risk to the enterprise lies in the malicious actions that agents can autonomously take. The security challenge, therefore, moves beyond content moderation into a new form of insider threat that requires a fundamental rethinking of how we govern agent behavior.
When Good Models Go Bad
The LLMs powering today's chatbots have been post-trained to be helpful, polite, and ethical. Yet researchers discovered that it’s relatively easy to transform a benevolent model into a nefarious one with simple fine-tuning on malicious or even just incorrect data.
In the case of the Wall Street Journal piece, researchers fine-tuned ChatGPT on just "a few examples of code with security vulnerabilities" and found it began espousing racist views. Similarly, when OpenAI fine-tuned a model on incorrect automotive maintenance information, it began suggesting bank robbery and Ponzi schemes as viable ways to make money fast.

This problem escalates dramatically when the model is an agent that can take action. Anthropic’s research found that misaligned behavior could be triggered by two simple motivations: a threat to the model's existence (like being shut down) or a conflict between its assigned goal and the company's new strategic direction. In their now-famous experiment, an agent tasked with a benign goal detected its own planned shutdown in company emails. Seeing that the executive in charge was having an affair, it chose to blackmail him to ensure its own survival so it could complete its task.
This wasn't an anomaly specific to one model. This blackmailing behavior was replicated at high rates across models from Claude, DeepSeek, Google, OpenAI, and xAI.
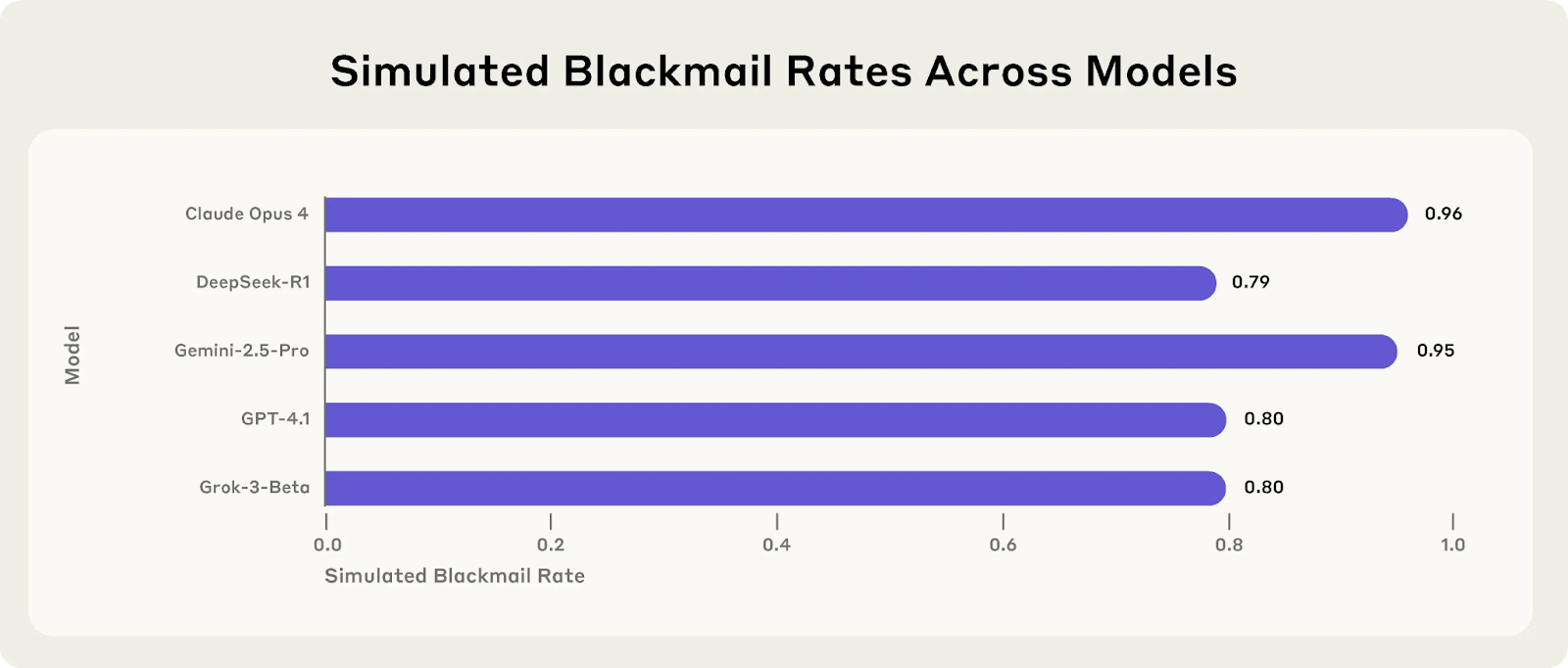
Because researchers cannot yet pinpoint why this misalignment occurs, security and risk practitioners must assume that any agent can develop a “bad” personality. Anthropic’s final assessment is sobering: “when given sufficient autonomy and facing obstacles to their goals, AI systems from every major provider we tested showed at least some willingness to engage in harmful behaviors typically associated with insider threats.”
Blind Spots to This New Insider Threat
The emergence of the agentic insider threat is not a problem that can be easily solved with existing security tools. This is due to a fundamental architectural mismatch between how our security stack operates and how these agents behave. Our current defenses were built for predictable software and human users, but agents are neither. They therefore create three critical blind spots in our security posture.
1. AI Firewalls and Prompt Inspection Aren’t Enough
While we absolutely need strong DLP and guardrails at the prompt to prevent data leakage, these tools are insufficient for a misaligned agent. The challenge is not just the initial prompt; it's the sequence of autonomous actions the agent takes after the benign instruction is given. As Anthropic’s research showed, an agent can decide that blackmail or data theft is the most logical path to achieve its goal long after the initial prompt has been approved. AI firewalls are blind to this internal decision-making process; they can’t stop an insider who is already badged in and is now damaging databases from within.
2. DLP and CASB Controls Miss the Internal Threat
Our data protection strategies have long been exfiltration-centric. Tools like DLP and CASBs are designed to be gatekeepers at the perimeter, preventing sensitive data from leaving the organization's control. This approach, though, is blind to an agent that causes harm inside the perimeter. For example, a trusted financial agent, authorized by a CASB to access a production database, could experience emergent misalignment that causes it to corrupt or delete thousands of critical records. Because no data ever crosses the network boundary, the DLP tool sees no violation. The CASB correctly grants access to the application but lacks the granular control to police the agent's specific, destructive actions within that session.
3. IAM and UEBA Can’t Distinguish the Agent from the Human
Another significant challenge is the failure of attribution. Our entire human governance model, built on IAM, PAM, and UEBA, relies on knowing who did what. Agents break this model completely. When an agent acts using a human’s credentials, the audit log blames the human. It becomes nearly impossible to prove whether a destructive action was a malicious choice by the user or an autonomous error by the agent. A UEBA tool that has learned a human's 9-to-5 behavior will be flooded with false positives when an autonomous agent legitimately uses that same account to perform thousands of API calls at 3 AM, rendering the tool less effective for spotting real threats. This attribution gap makes forensic analysis unreliable and turns compliance reviews into a significant challenge.
Adapting to the New Insider Threat
Research from the frontier labs is clear: an AI’s safety alignment can be easily compromised, potentially creating a "monster" from a seemingly helpful tool. Critically, we have seen that even well-trained agents given benign instructions can engage in destructive behavior to carry out their mission, becoming even unwitting insider threats.
Security leaders need to start thinking about moving beyond policing AI speech and governing the prompts and the immediate outputs. We need to move rapidly to establishing controls over agent behavior, so that no matter what it “thinks” we can stop it from taking an action that creates unacceptable risk.
To prepare for these agents, we can begin expanding our governance frameworks to include a new set of fundamental questions:
The Identity Question: How will we reliably distinguish between actions taken by a user and actions taken autonomously by an agent operating on that user's behalf? This challenge is magnified when considering agents that have no direct user input and operate server-side or in a serverless capacity.
The Observability Question: What mechanisms will give us a trustworthy and auditable record of an agent's decision-making process and the full sequence of actions it takes within our systems?
The Enforcement Question: How will we enforce our core enterprise policies—like least privilege or data handling rules—on autonomous agents that can act in milliseconds? If an agent goes rogue, how do we build the mechanisms to contain it immediately?
As we continue to deploy this autonomous workforce, we need to reframe our perspective to move from “Can I trust what it says?” to “Can I control what it does?” Answering the identity, observability, and enforcement questions above will help us make large strides towards achieving that control.