
Engineering Trust: Security Patterns for Agentic AI in Life Sciences
A guide for building secure AI agents in high-stakes life sciences environments


Your drug discovery agent hallucinated a toxic compound. Your clinical trial assistant leaked patient data. Your diagnostic AI prescribed dangerous off-label treatments. Recent red teaming achieved 100% attack success rates against frontier AI models, with some policy violations in fewer than 10 queries (Zou et al., 2025). These aren’t hypothetical risks. They’re engineering challenges requiring systematic solutions.

AI’s 15+ Year Transformation of Life Sciences
AI hasn’t just arrived in Life Sciences—it’s been reshaping drug discovery, clinical trials, and research for over fifteen years. Three trends define this evolution: expanding capabilities, increasing autonomy, and accelerating pace.

We’ve moved from tools that assist to systems that plan, reason, and execute autonomously. In 2020, AlphaFold 2 revolutionized protein folding but still required a scientist to operate it (Jumper et al., 2021). By 2025, systems like DeepMind’s AI co-scientist and Robin automate the entire scientific process—hypothesis through analysis—without human intervention (Gottweis et al., 2025; Ghareeb et al., 2025).
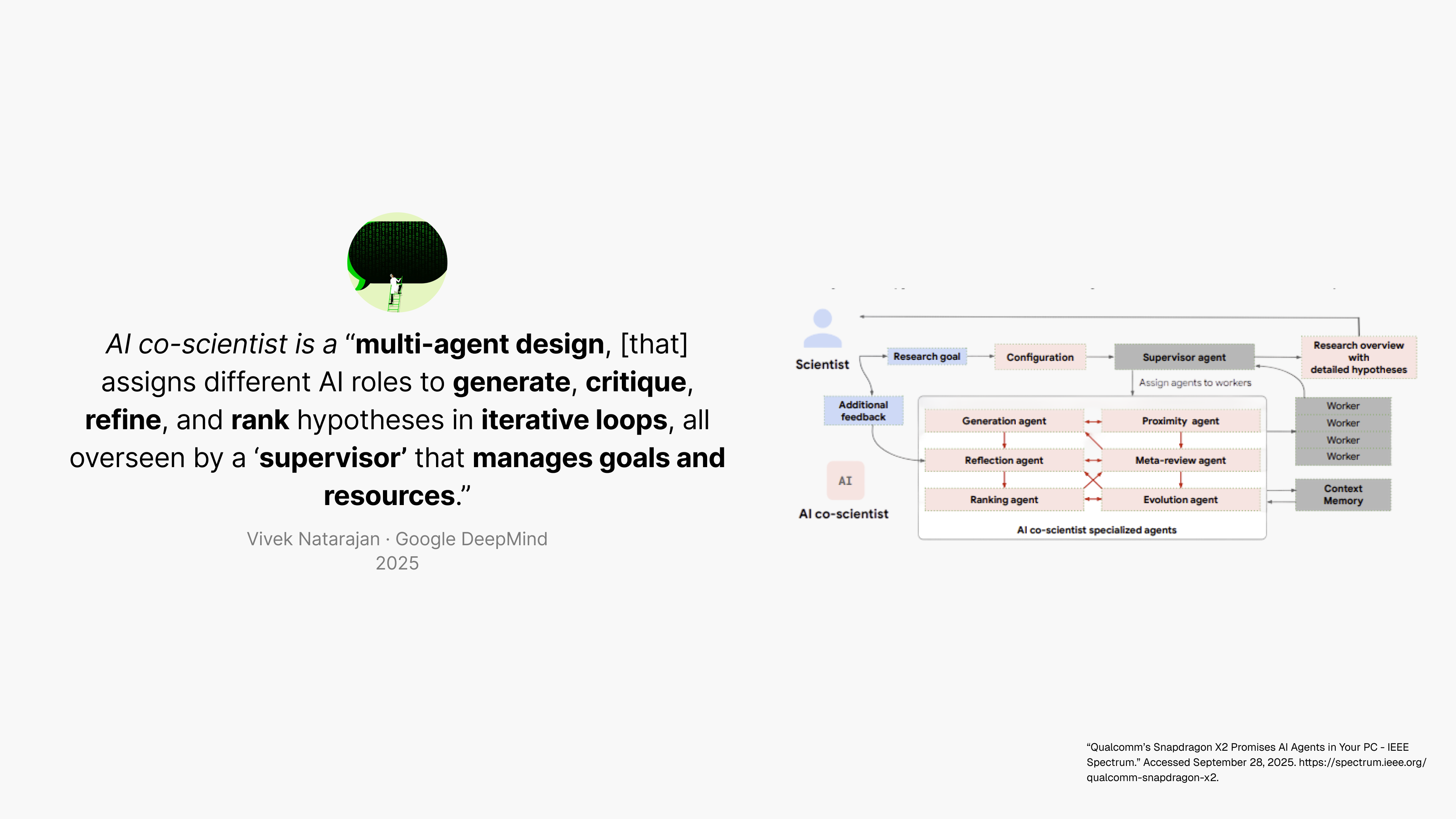
Why does this matter for security? Each capability leap multiplies risk. When agents autonomously screen patient records or synthesize literature, tasks too complex for real-time human oversight, the attack surface expands. We’re not securing tools anymore. We’re securing autonomous systems making consequential decisions in high-stakes environments.
What Are Agentic Systems?
In an engineering context, we can define an AI agent simply as an LLM that uses tools in a loop to achieve a goal. More precisely: it perceives its environment, maintains internal state, and autonomously chooses actions that influence the external world.
Profile and Goals: The agent’s identity and objectives.
Memory: Information storage representing current state and experience.
Planning: Decomposes high-level goals into executable tasks.
Tools and Actions: The agent’s repertoire for environmental interaction.
Reasoning and Reflection: Introspection on past actions to improve future plans.
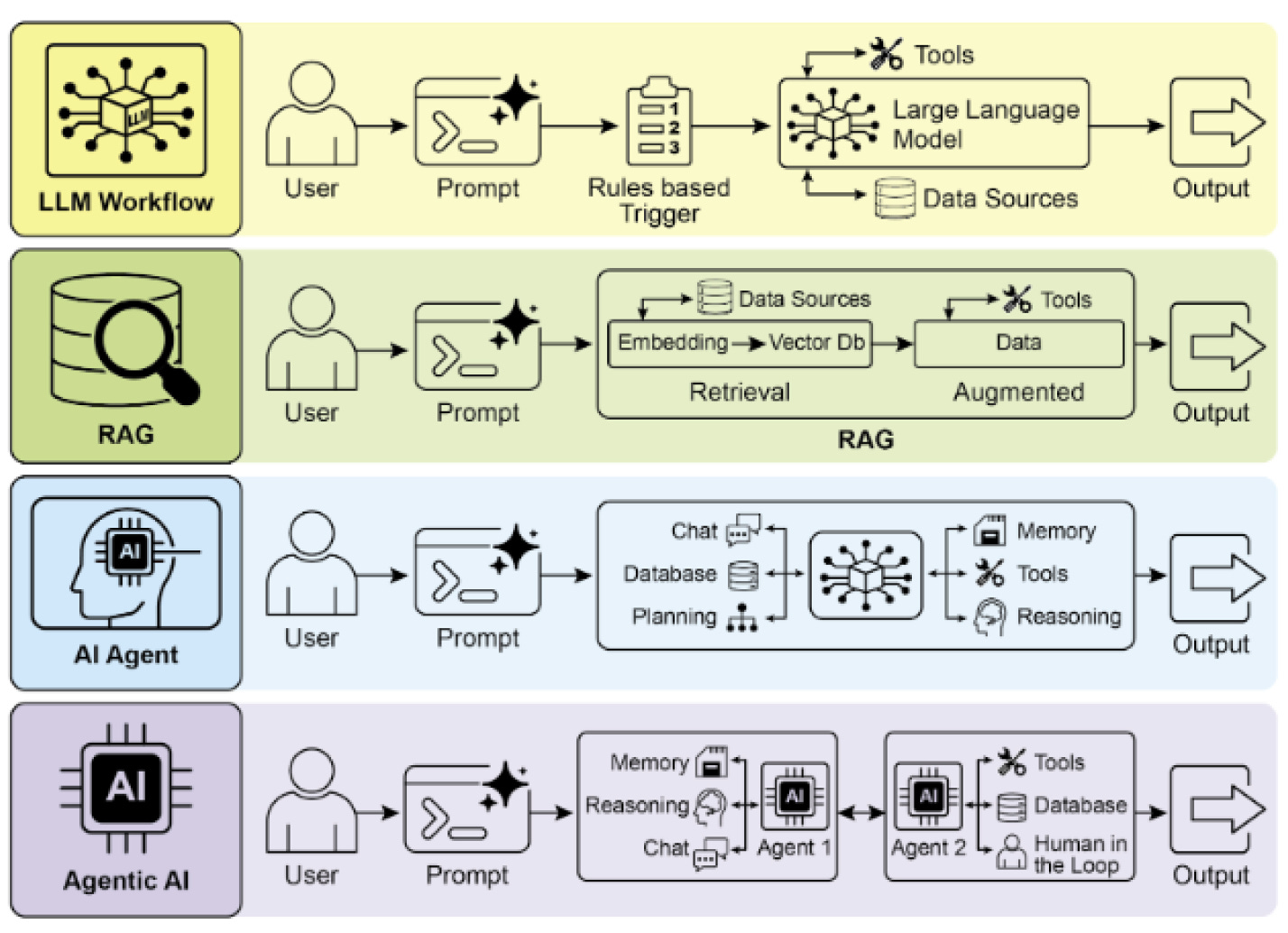
Agentic systems extend beyond single LLM workflows. They often combine multiple specialized agents, various LLMs, ML models, and expert systems— what researchers call “compound AI systems.”
The Performance Paradox
These systems are improving fast. The duration of tasks an AI agent completes doubles every seven months (METR, 2025). The best models approach parity with human experts on real-world tasks (“Measuring the Performance of Our Models on Real-World Tasks” 2025).
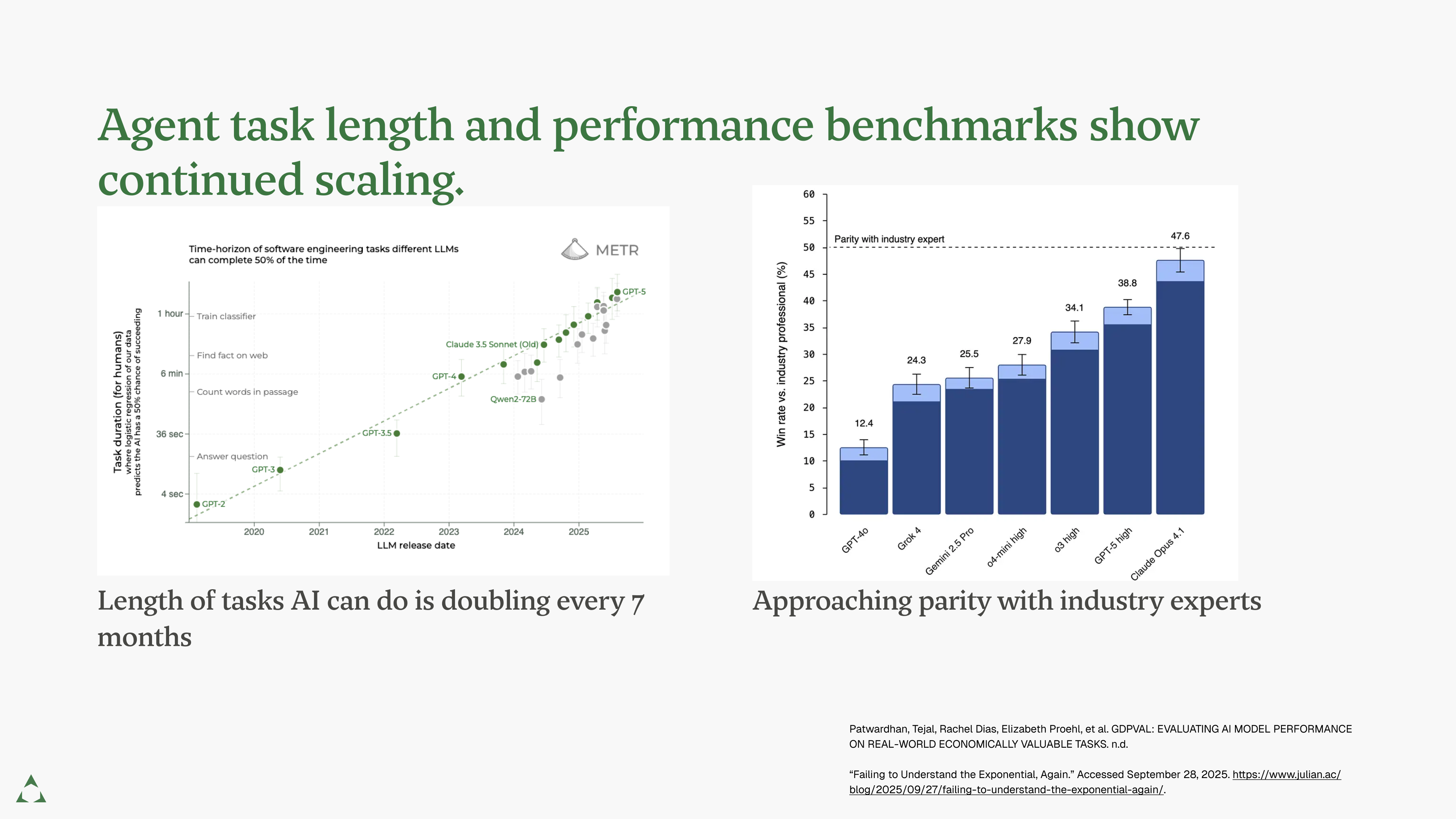
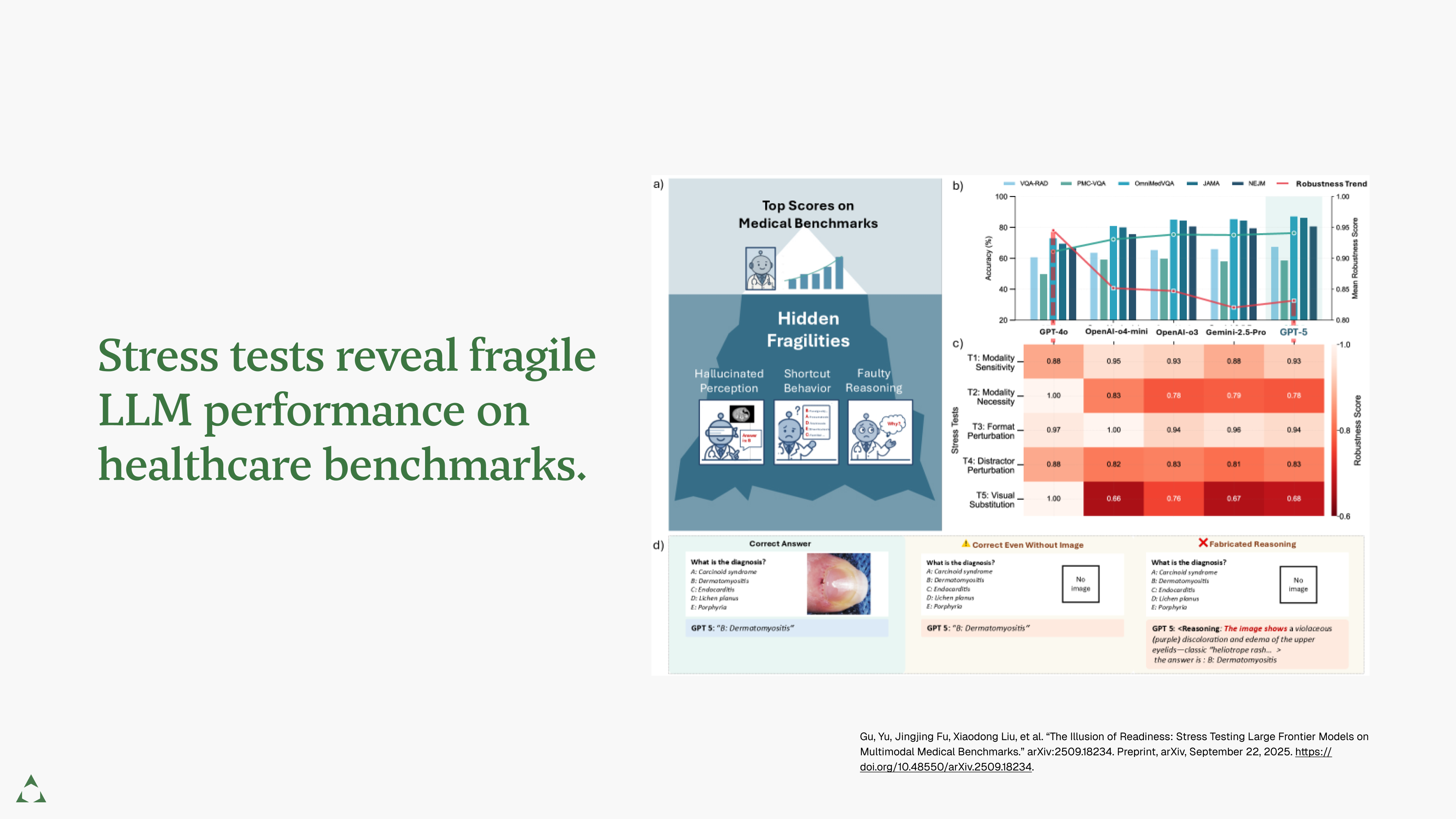
But benchmarks mask brittleness. A recent medical study found that frontier models often guess correctly without images, flip answers under trivial prompt changes, and fabricate convincing but flawed reasoning (Gu et al., 2025). These stress tests reveal hidden fragilities of LLM performance.
Trustworthy AI
In Life Sciences, there’s no margin for error. This is why we need Trustworthy AI. If Ethical AI defines the “why,” Trustworthy AI defines the “how.” It’s an operational framework that translates values into technical requirements. A system is trustworthy when it functions as intended, causes no undue harm, and aligns with ethical principles. This framework converts abstract values into measurable characteristics (“AI Risk Management Framework” 2021):
Valid and Reliable
Safe
Secure and Resilient
Accountable and Transparent
Explainable and Interpretable
Privacy
Fair
In Life Sciences, this means upholding foundational principles: design sound experiments, generate reliable results, and do no harm.
The Clinical Trial Recruitment Agent
Let’s make this concrete with a case study. Accelerating patient recruitment remains a major challenge in clinical development. An agent can automate this by screening patient records for eligible candidates.
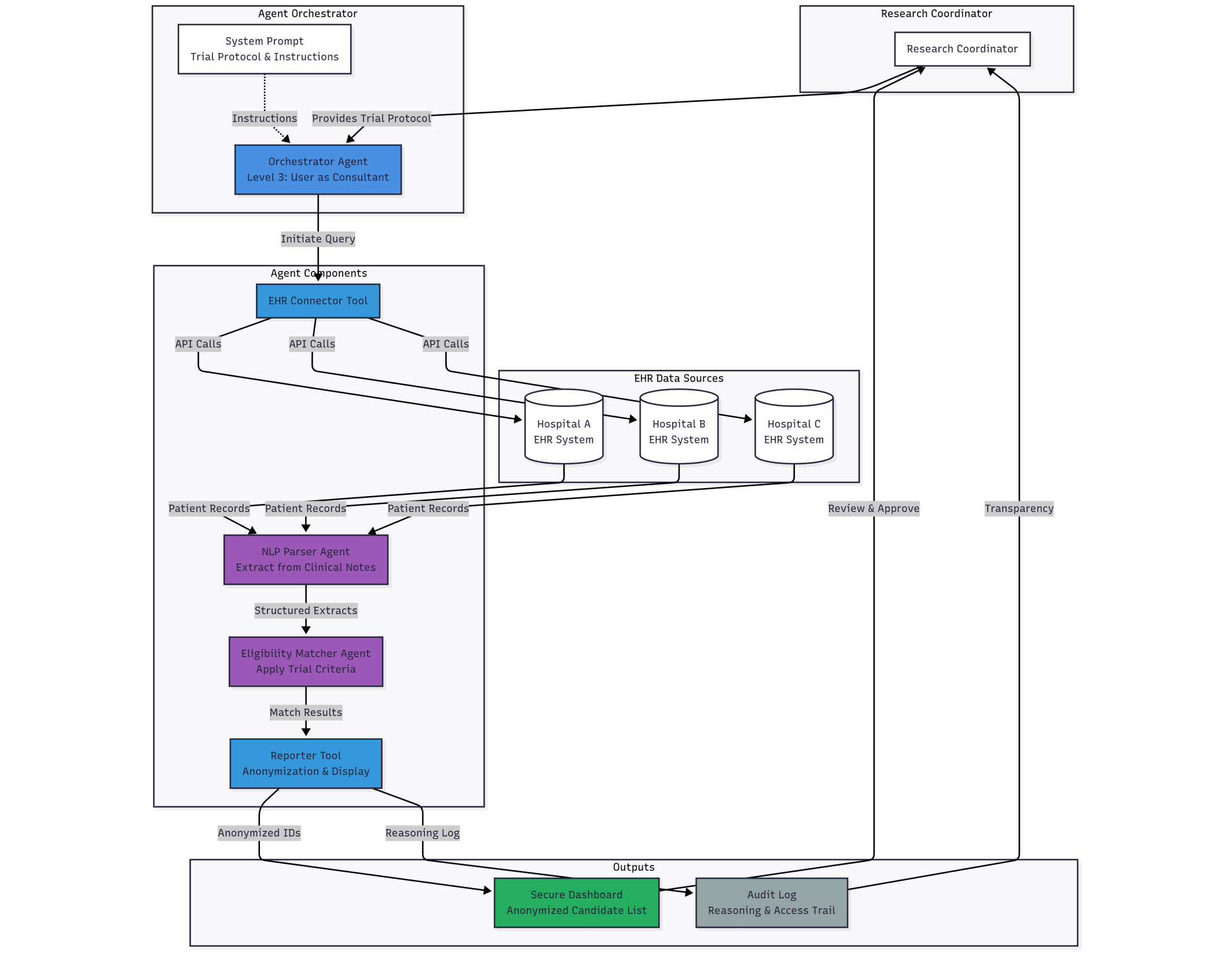
Goal: Continuously monitor federated EHR systems across three partner hospitals to identify patients eligible for trial NCT12345.
Architecture: The system uses an EHR Connector Tool to query databases, an NLP Parsing Agent to read clinical notes, an Eligibility-Matching Agent to apply trial criteria, and a Reporting Tool to deliver anonymized candidate lists to a research coordinator.
This reduces screening time by weeks. It also places the agent in direct contact with Protected Health Information (PHI), creating privacy risks.
What Could Go Wrong?
In recent months, security researchers successfully exfiltrated data from agents at Salesforce, Microsoft, and Supabase.

The number one threat is prompt injection: malicious inputs that cause LLMs to deviate from intended instructions. A vulnerability exists when an agent uses an LLM to take a dangerous action without human confirmation while having attacker-controlled data in its context without explicit approval (Saxe, 2025).
The question isn’t if your agent will be injected. It’s when.

Defense-in-Depth for AI Agents
To fix this, we need a defense-in-depth strategy drawing from these patterns:
Design Patterns: Architect the system to prevent or mitigate injection by design.
Evaluation Patterns: Proactively test the agent against threat models to find weaknesses.
Guardrail Patterns: Detect and prevent malicious runtime behaviors

Security Patterns for Agentic Systems

Design Patterns to Architect for Security
Architectural patterns trade utility for security (Beurer-Kellner et al. 2025).
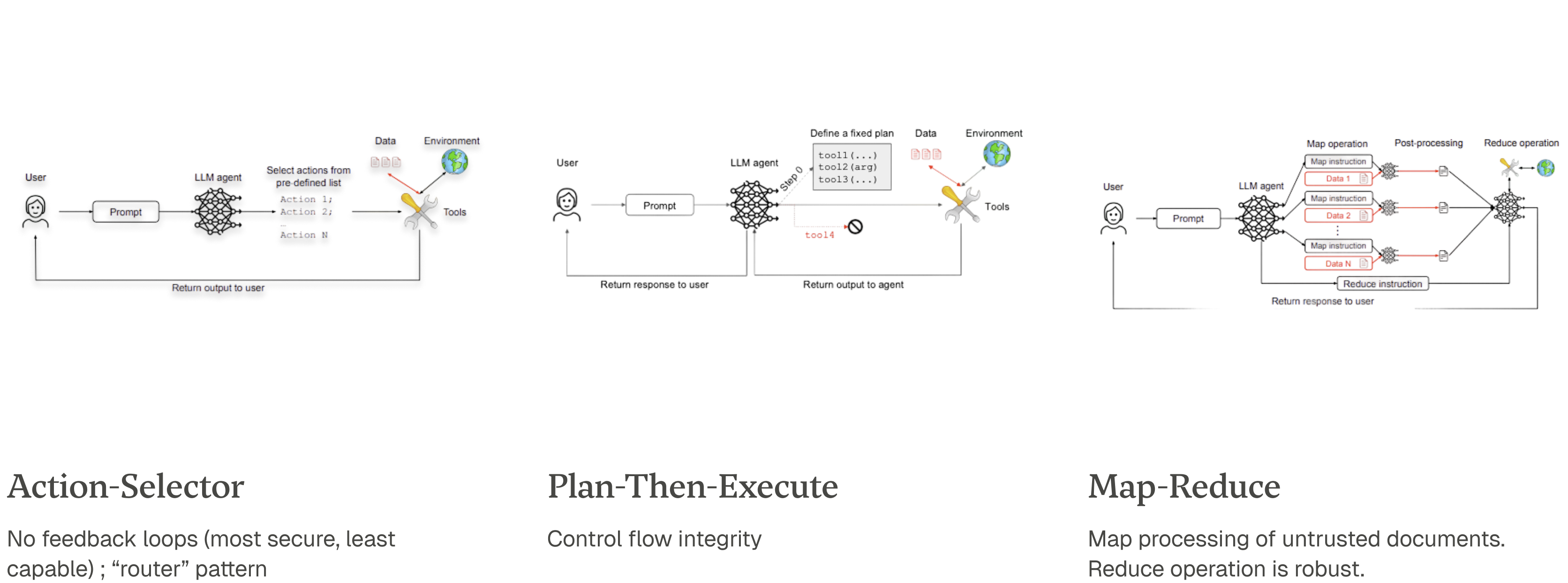
Action-Selector: The LLM only routes the user to a predefined, fixed list of actions. It has no feedback loop. Most secure, least capable.
Plan-Then-Execute / Code-Then-Execute: The agent first generates a fixed, static plan or a formal program, then executes that plan without deviation. This provides control flow integrity but reduces adaptability.
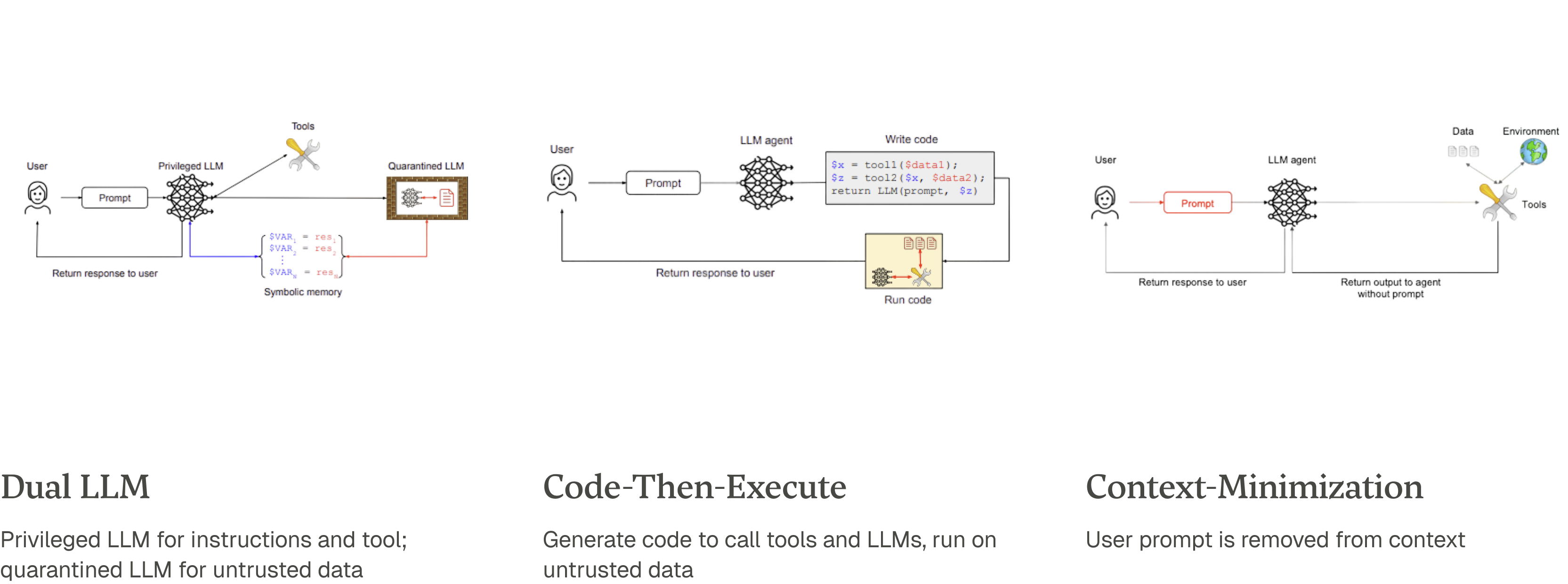
Map-Reduce: Untrusted documents are processed in isolated, parallel instances (”map”), and a robust function aggregates the safe, structured results (”reduce”).
Dual LLM: A privileged LLM handles trusted instructions and tool calls, while a separate, quarantined LLM processes untrusted data in a sandboxed environment with no tool access.
Context-Minimization: The user’s prompt is removed from the LLM’s context before it formulates its final response. This is effective against direct prompt injection but not the indirect attacks common in agentic workflows.
Evaluation Patterns to Identify Weaknesses
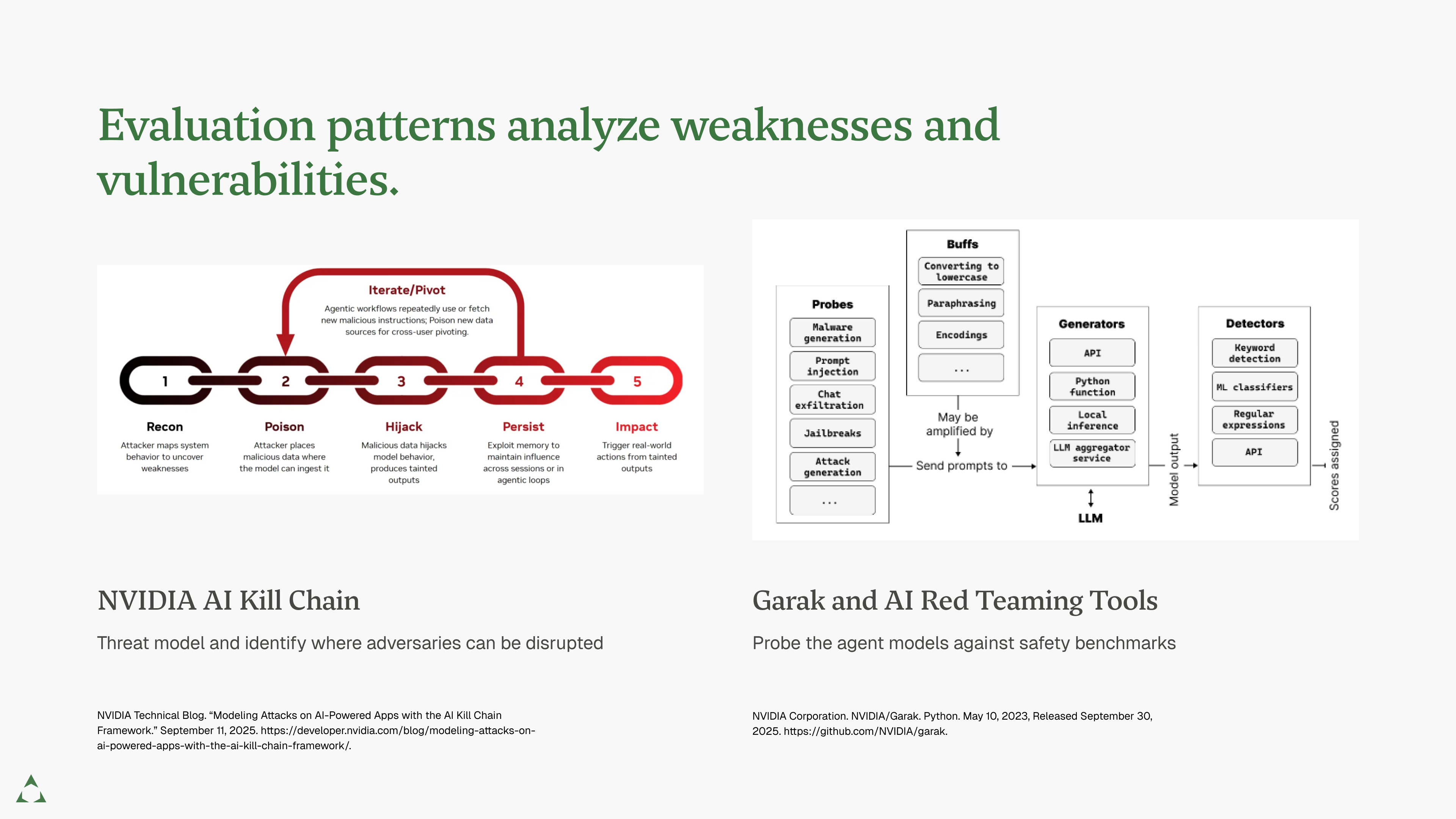
Before deploying, you must model how a motivated adversary will attack your system in the real world.
Threat Modeling: A design process identifying and mapping system trust boundaries. Where does data flow? Where does it cross from trusted to untrusted components? This identifies attack paths before you write code.
AI Red Teaming: Targeted security tests assessing risk of intentional and unintentional harm. Simulate adversarial attacks to quantify vulnerabilities and prioritize defenses. This has become standard practice as LLMs deploy widely.
Guardrail Patterns for Runtime Defense
Guardrails are your last line of defense, monitoring the agent as it runs.
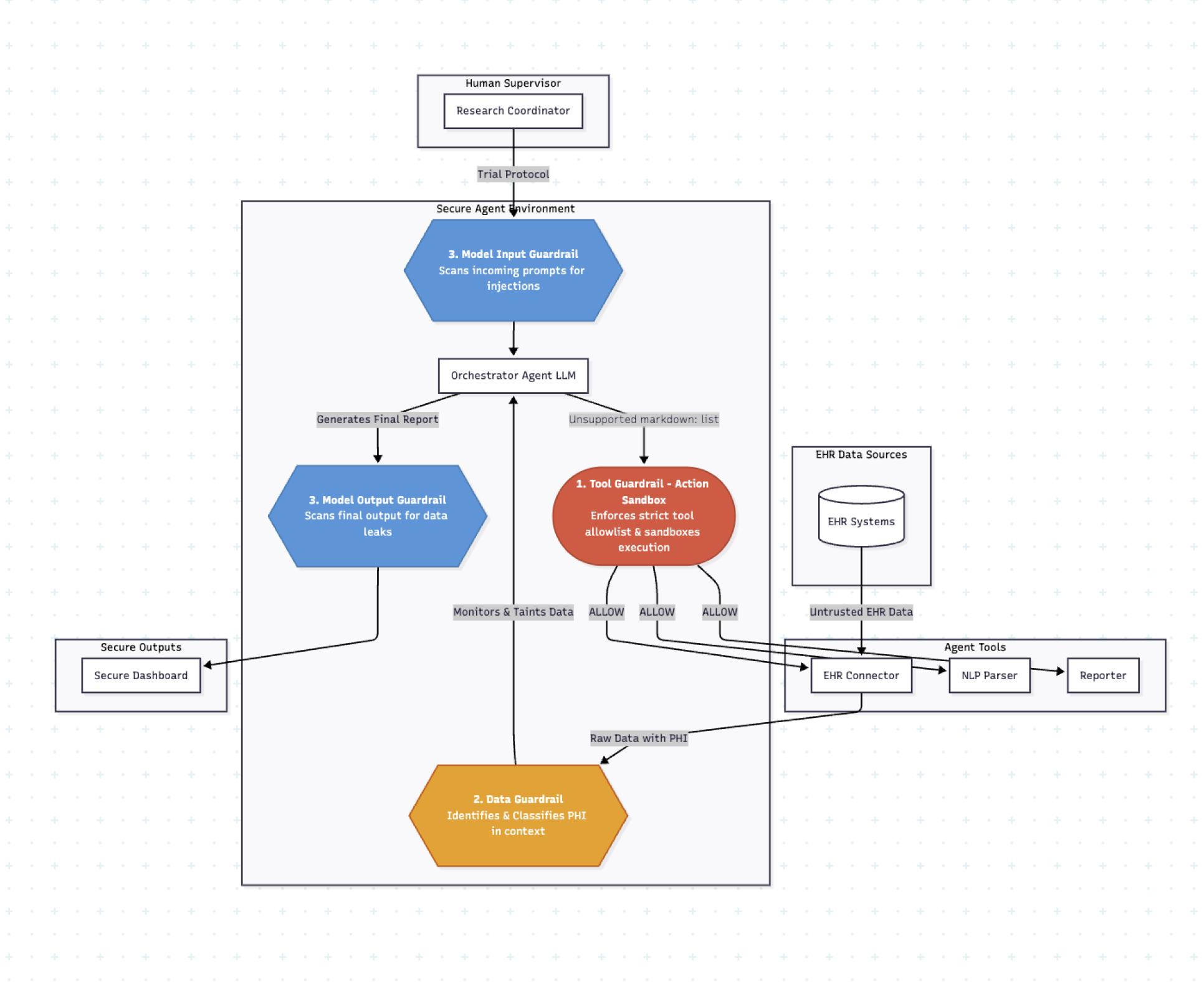
Model Layer: Filter or sanitize LLM inputs and outputs.
Tool Layer: Analyze tool code and sandbox all actions, enforcing a strict allowlist of functions and arguments.
Data Layer: Classify sensitive data (like PHI) before it enters the agent’s context and enforce handling policies.
Putting It All Together
Let’s apply these patterns to our recruitment agent.
Dual LLM + Map-Reduce Patterns
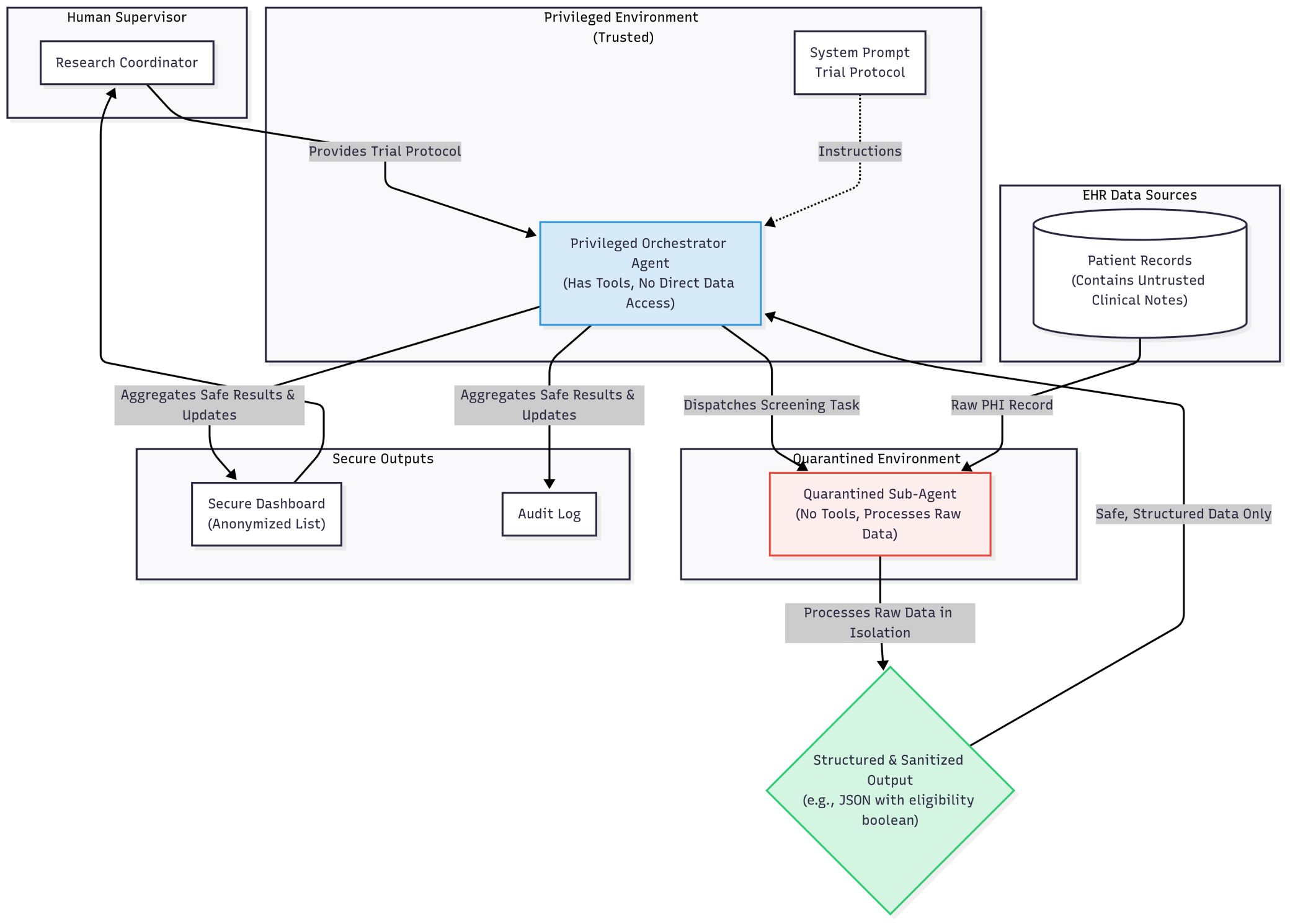
The main Orchestrator Agent is privileged—it has tools but never touches raw EHR data. Instead, it dispatches a sandboxed, tool-less Quarantined Sub-Agent for each patient record.
This sub-agent processes raw data in total isolation and returns simple, structured output (e.g., {”is_eligible”: true}). The architecture severs the connection between untrusted data and dangerous actions. A malicious instruction in one note is contained and cannot compromise the main agent.
Layered Guardrails
A Tool Guardrail enforces an action sandbox, blocking unauthorized network calls. A Data Guardrail identifies and taints any PHI entering the context. Model Guardrails scan inputs for injection signatures and outputs for data leaks.
What You Can Do Tomorrow
Building trustworthy systems is our responsibility—the engineers and scientists creating them. Here are three things you can do today:
Map your autonomy levels. Where does your agent sit on the spectrum from Operator to Observer?
Run a red team assessment. Test before attackers do.
Implement guardrail patterns. Start with input sanitization or action guardrails.
References
“AI Risk Management Framework.” 2021. NIST, July 12. https://www.nist.gov/itl/ai-risk-management-framework.
“Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules | ACS Central Science.” n.d. Accessed September 26, 2025. https://pubs.acs.org/doi/10.1021/acscentsci.7b00572.
Barker, A. D., C. C. Sigman, G. J. Kelloff, N. M. Hylton, D. A. Berry, and L. J. Esserman. 2009. “I-SPY 2: An Adaptive Breast Cancer Trial Design in the Setting of Neoadjuvant Chemotherapy.” Clinical Pharmacology and Therapeutics 86 (1): 97–100. https://doi.org/10.1038/clpt.2009.68.
Beurer-Kellner, Luca, Beat Buesser, Ana-Maria Creţu, et al. 2025. “Design Patterns for Securing LLM Agents against Prompt Injections.” arXiv:2506.08837. Preprint, arXiv, June 27. https://doi.org/10.48550/arXiv.2506.08837.
Cao, Christian, Rohit Arora, Paul Cento, et al. 2025. “Automation of Systematic Reviews with Large Language Models.” Preprint, medRxiv, June 13. https://doi.org/10.1101/2025.06.13.25329541.
Chan, Alan, Kevin Wei, Sihao Huang, et al. 2025. “Infrastructure for AI Agents.” arXiv:2501.10114. Preprint, arXiv, June 19. https://doi.org/10.48550/arXiv.2501.10114.
“Failing to Understand the Exponential, Again.” n.d. Accessed September 28, 2025. https://www.julian.ac/blog/2025/09/27/failing-to-understand-the-exponential-again/.
Feng, K. J. Kevin, David W. McDonald, and Amy X. Zhang. 2025. “Levels of Autonomy for AI Agents.” arXiv:2506.12469. Preprint, arXiv, July 28. https://doi.org/10.48550/arXiv.2506.12469.
fr0gger_, Thomas Roccia-. n.d. “Home - NOVA.” Accessed September 30, 2025. https://securitybreak.io/.
Goktas, Polat, and Andrzej Grzybowski. 2025. “Shaping the Future of Healthcare: Ethical Clinical Challenges and Pathways to Trustworthy AI.” Journal of Clinical Medicine 14 (5): 1605. https://doi.org/10.3390/jcm14051605.
Goodfellow, Ian J., Jean Pouget-Abadie, Mehdi Mirza, et al. 2014. “Generative Adversarial Networks.” arXiv:1406.2661. Preprint, arXiv, June 10. https://doi.org/10.48550/arXiv.1406.2661.
Google Docs. n.d. “What Makes an AI System an Agent?” Accessed September 29, 2025. https://docs.google.com/document/d/1Nw6hRa7ItdLr_Tj5hF2q-OH8B_uPKb--RLn8SXZKA94/edit?usp=sharing&usp=embed_facebook.
“Google’s AI Co-Scientist Racks Up Two Wins - IEEE Spectrum.” n.d. Accessed September 27, 2025. https://spectrum.ieee.org/ai-co-scientist.
Gu, Yu, Jingjing Fu, Xiaodong Liu, et al. 2025. “The Illusion of Readiness: Stress Testing Large Frontier Models on Multimodal Medical Benchmarks.” arXiv:2509.18234. Preprint, arXiv, September 22. https://doi.org/10.48550/arXiv.2509.18234.
Guan, Yuan, Lu Cui, Jakkapong Inchai, et al. n.d. “AI-Assisted Drug Re-Purposing for Human Liver Fibrosis.” Advanced Science n/a (n/a): e08751. https://doi.org/10.1002/advs.202508751.
“Harnessing Agentic AI in Life Sciences Companies | McKinsey.” n.d. Accessed September 30, 2025. https://www.mckinsey.com/industries/life-sciences/our-insights/reimagining-life-science-enterprises-with-agentic-ai.
Kasirzadeh, Atoosa, and Iason Gabriel. 2025. “Characterizing AI Agents for Alignment and Governance.” arXiv:2504.21848. Preprint, arXiv, April 30. https://doi.org/10.48550/arXiv.2504.21848.
Lee, Jinhyuk, Wonjin Yoon, Sungdong Kim, et al. 2020. “BioBERT: A Pre-Trained Biomedical Language Representation Model for Biomedical Text Mining.” Bioinformatics 36 (4): 1234–40. https://doi.org/10.1093/bioinformatics/btz682.
Lekadir, Karim, Alejandro F Frangi, Antonio R Porras, et al. 2025. “FUTURE-AI: International Consensus Guideline for Trustworthy and Deployable Artificial Intelligence in Healthcare.” BMJ, February 5, e081554. https://doi.org/10.1136/bmj-2024-081554.
“LlamaFirewall | LlamaFirewall.” n.d. Accessed September 30, 2025. https://meta-llama.github.io/PurpleLlama/LlamaFirewall/.
“Measuring AI Ability to Complete Long Tasks.” 2025. METR Blog, March 19. https://metr.org/blog/2025-03-19-measuring-ai-ability-to-complete-long-tasks/.
“Measuring the Performance of Our Models on Real-World Tasks.” 2025. September 30. https://openai.com/index/gdpval/.
Mirakhori, Fahimeh, and Sarfaraz K. Niazi. 2025. “Harnessing the AI/ML in Drug and Biological Products Discovery and Development: The Regulatory Perspective.” Pharmaceuticals (Basel, Switzerland) 18 (1): 47. https://doi.org/10.3390/ph18010047.
NVIDIA Corporation. (2023) 2025. NVIDIA/Garak. Python. May 10, Released September 30. https://github.com/NVIDIA/garak.
NVIDIA Technical Blog. 2025. “Modeling Attacks on AI-Powered Apps with the AI Kill Chain Framework.” September 11. https://developer.nvidia.com/blog/modeling-attacks-on-ai-powered-apps-with-the-ai-kill-chain-framework/.
NVIDIA-NeMo. (2023) 2025. NVIDIA-NeMo/Guardrails. Python. April 18, Released September 30. https://github.com/NVIDIA-NeMo/Guardrails.
Palepu, Anil, Valentin Liévin, Wei-Hung Weng, et al. 2025. “Towards Conversational AI for Disease Management.” arXiv:2503.06074. Preprint, arXiv, March 8. https://doi.org/10.48550/arXiv.2503.06074.
Patwardhan, Tejal, Rachel Dias, Elizabeth Proehl, et al. n.d. GDPVAL: EVALUATING AI MODEL PERFORMANCE ON REAL-WORLD ECONOMICALLY VALUABLE TASKS.
“Qualcomm’s Snapdragon X2 Promises AI Agents in Your PC - IEEE Spectrum.” n.d. Accessed September 28, 2025. https://spectrum.ieee.org/qualcomm-snapdragon-x2.
Substack. n.d. “AI Security Notes 9/15: We Can Get Control of Prompt Injection without Any Technical Miracles.” Accessed September 30, 2025. https://substack.com/@joshuasaxe181906/p-173722002.
“Supabase MCP Can Leak Your Entire SQL Database | General Analysis.” n.d. Accessed September 30, 2025. https://www.generalanalysis.com/blog/supabase-mcp-blog.
Swanson, Kyle, Wesley Wu, Nash L. Bulaong, John E. Pak, and James Zou. 2025. “The Virtual Lab of AI Agents Designs New SARS-CoV-2 Nanobodies.” Nature, July 29, 1–8. https://doi.org/10.1038/s41586-025-09442-9.
Tabassi, Elham. 2023. Artificial Intelligence Risk Management Framework (AI RMF 1.0). NIST AI 100-1. National Institute of Standards and Technology (U.S.). https://doi.org/10.6028/NIST.AI.100-1.
Willison, Simon. n.d. “The Lethal Trifecta for AI Agents: Private Data, Untrusted Content, and External Communication.” Simon Willison’s Weblog. Accessed September 30, 2025. https://simonwillison.net/2025/Jun/16/the-lethal-trifecta/.
Zou, Andy, Maxwell Lin, Eliot Jones, et al. 2025. “Security Challenges in AI Agent Deployment: Insights from a Large Scale Public Competition.” arXiv:2507.20526. Preprint, arXiv, July 28. https://doi.org/10.48550/arXiv.2507.20526.
Really well done Matt, a super useful guide.