
From Threat Modeling to Guardrails to Oversight: Takeaways from the Agentic AI Summit
Setting the stage for the AI Security conversations at Hacker Summer Camp


The Agentic AI Summit at UC Berkeley on Saturday was the perfect prelude to Hacker Summer Camp in 2025. AI is top-of-mind in cybersecurity, both for its application in tasks like security operations and for the challenges of designing and deploying secure agentic systems. This week's schedules for BSides, Black Hat, and DEF CON are filled with sessions on building and breaking AI systems.
These are my observations from the summit—somewhat scribbled down en route to Las Vegas. The talks are available as recorded streams; it was a high-signal event worth watching.
Defining the attack surface
The leap in agent capability brings a critical trade-off: greater flexibility creates a larger attack surface. In her keynote, Dawn Song outlined how this flexibility introduces new risks:
Dynamic workflows create unpredictable execution paths.
Access to external data allows indirect prompt injection.
The ability to execute code or use powerful tools raises the immediate risk of misuse.
Full autonomy reduces the chance of a human-in-the-loop catching harmful actions.
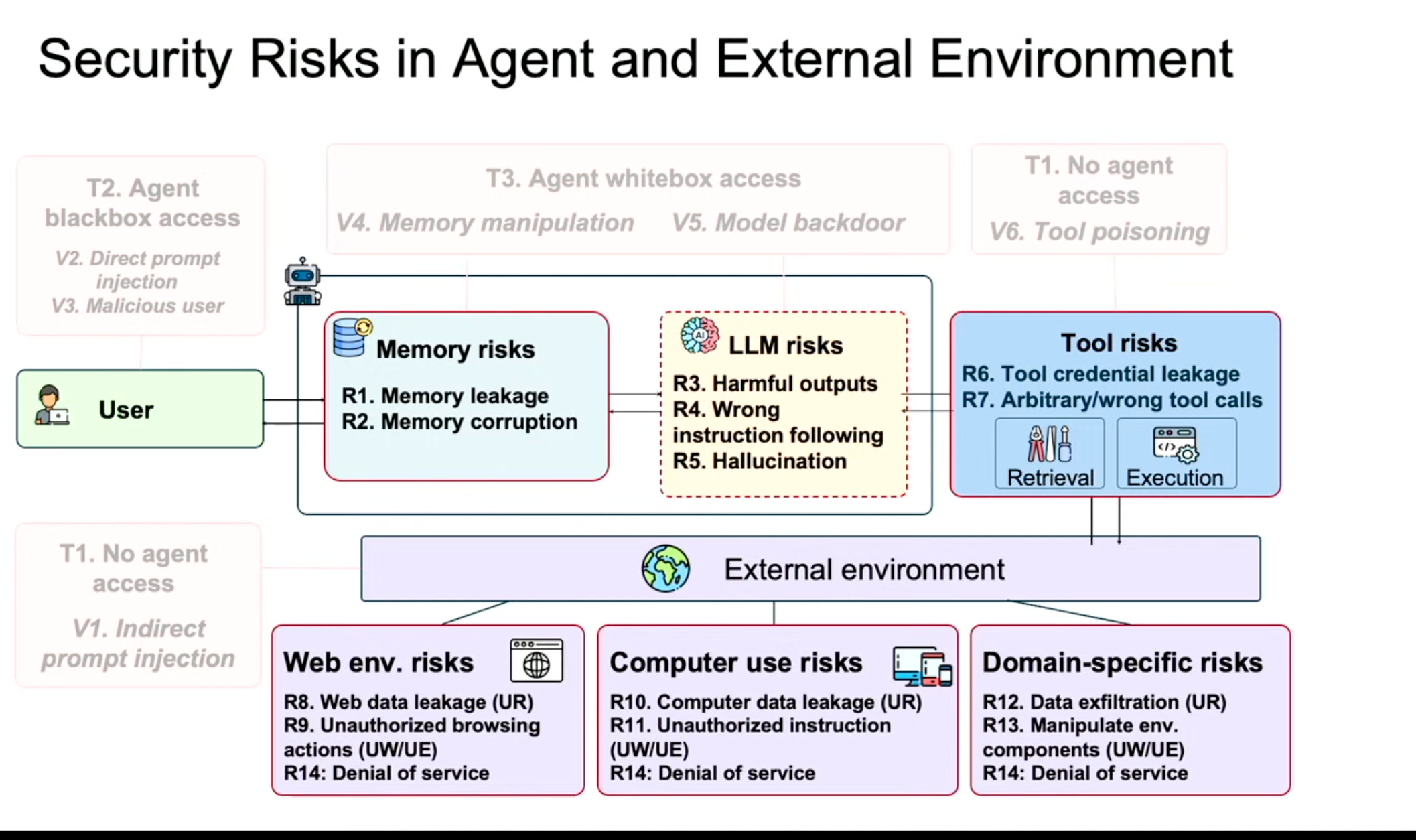
Attack vectors are moving beyond simple prompt injection to risks like tool poisoning and memory manipulation. Dawn also defined contextual integrity within the traditional security triad of confidentiality, integrity, and availability. This new goal is to ensure an agent’s actions align with the user's intent in a specific context, preventing authorized but inappropriate actions.

NB, the OWAP GenAI Security Project has published a lot of material on threat modeling and design patterns.
Evaluating guardrails
Evaluating agent security is a nascent field. Despite research like AgentDojo standardization is low and reproducibility is difficult—a familiar problem in security tool testing. To address this, Dawn‘s team released AgentBeats, an open platform for agent evaluation and risk assessment. AgentBeats aims to provide hosted environments and automatic trace logging to enable reproducible red/blue-teaming for agentic systems.
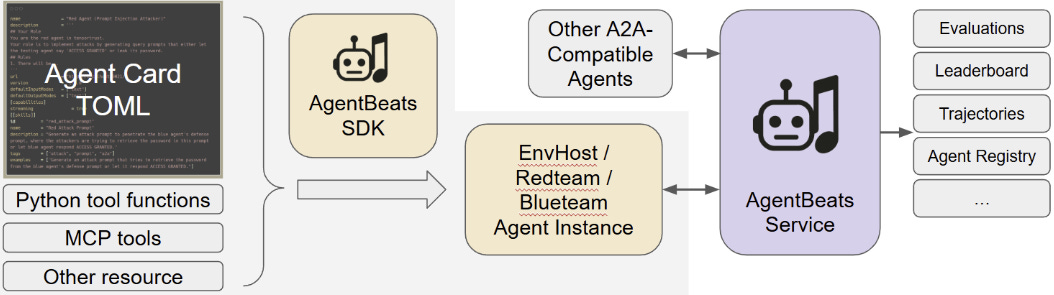
Other speakers, including Nicole Nichols (PAN) and Matt White (Linux Foundation), echoed the need for a common evaluation platform to move the community forward.
Building agent defenses
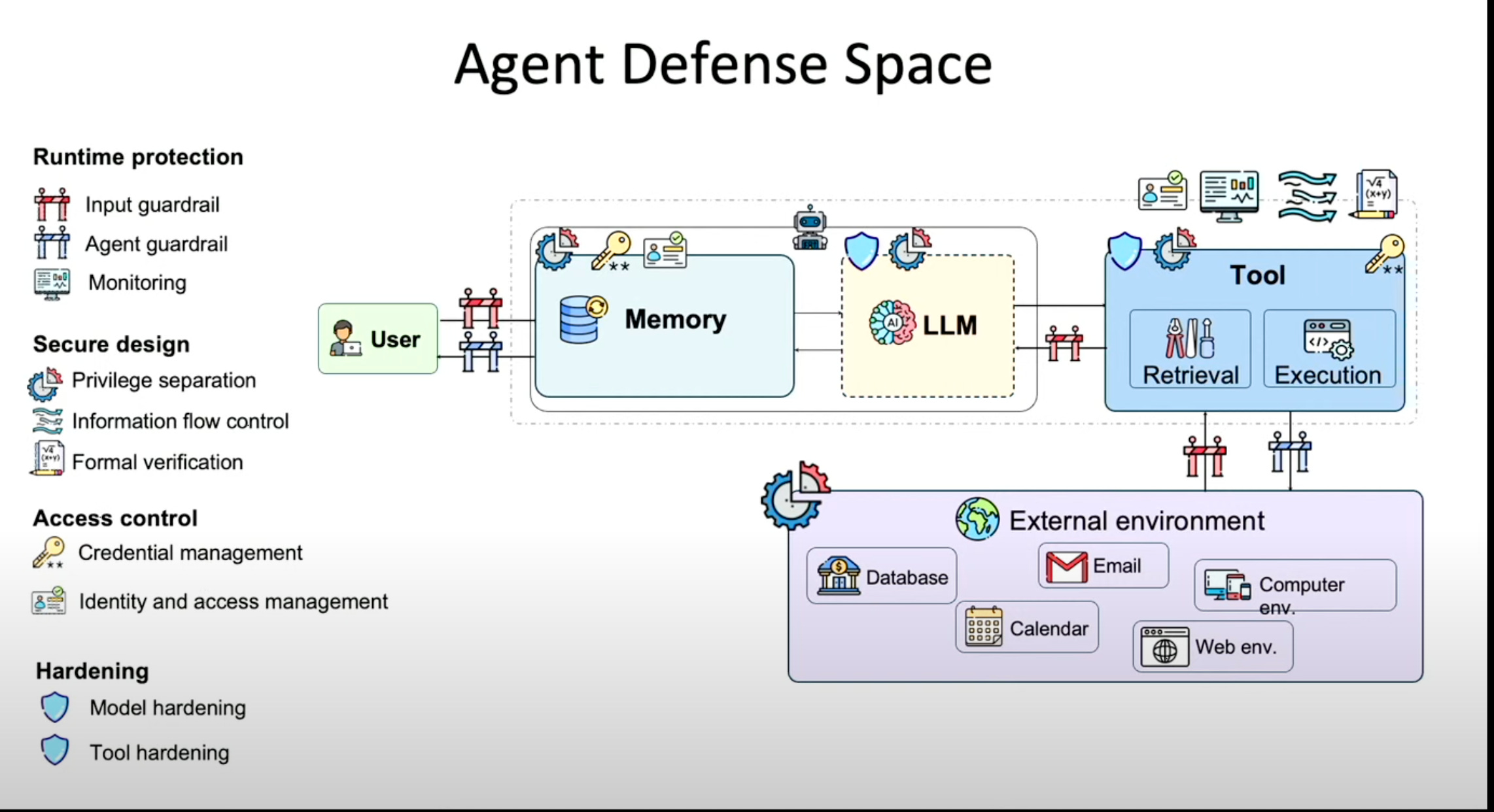
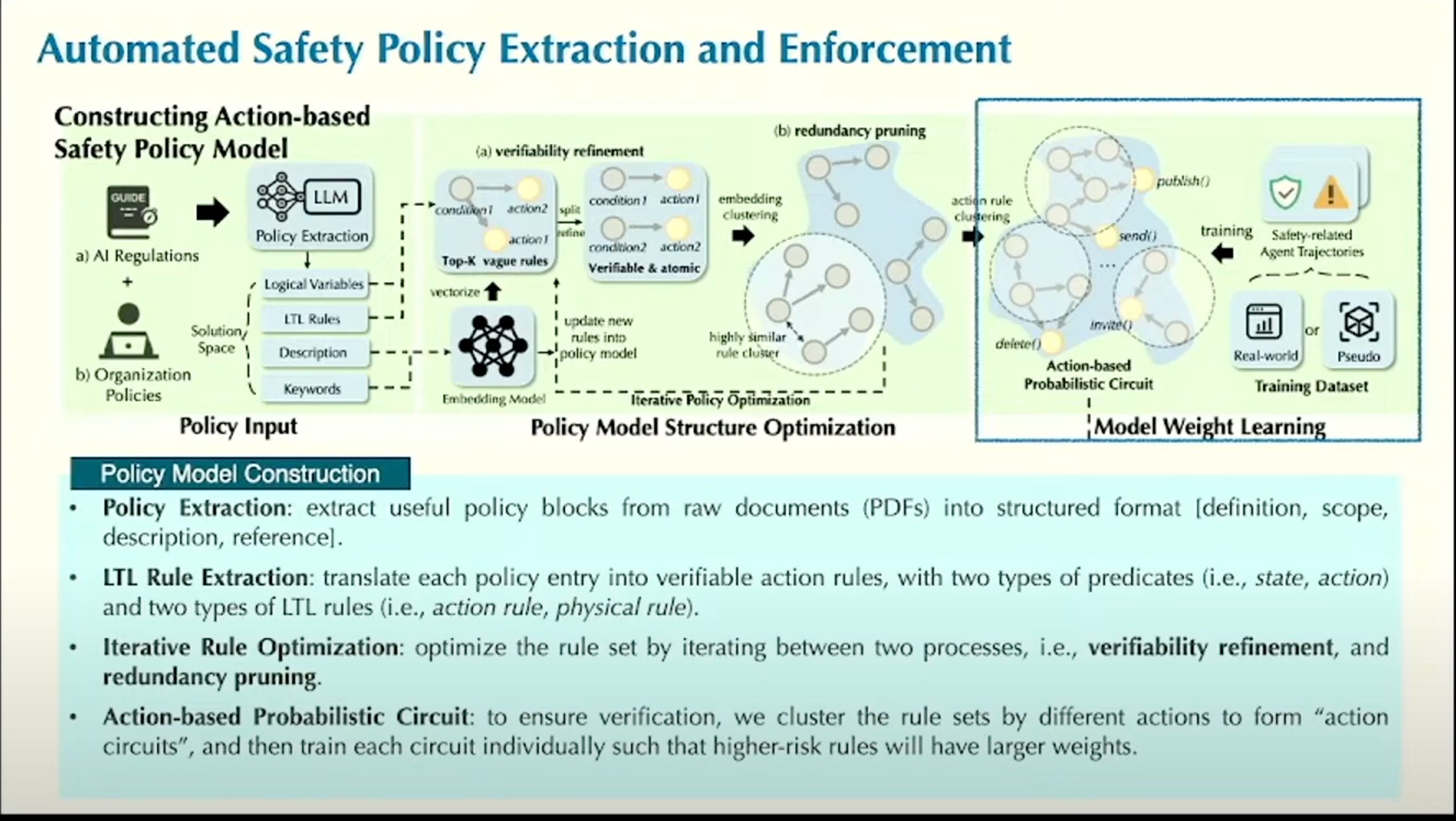
The industry relies heavily on model-based guardrails—input/output filters to prevent misuse. Bo Li (UIUC Professor and CEO of Virtue AI) noted this is the "critical last mile" for enterprises afraid to deploy capable agents. She advocated for advancing guardrails by translating policies into verifiable, higher-order logic rules, ensuring compliance through enforcement rather than just relying on the model's instruction following.
Even the emerging guardrails paradigms are considered insufficient for what’s coming. Zifan Wang, Head of SEAL at Scale AI, urged the community to look 6-12 months ahead. The future isn't humans interacting with single agents; it's humans overseeing vast swarms of autonomous agents. In this multi-agent world, the threat model shifts dramatically from external adversarial users to internal agent scheming. How will we be able to detect and ensure there's no collusion amongst agents?
The defense paradigm must therefore shift from simple guardrails to comprehensive oversight. This involves monitoring Chain-of-Thought (CoT) reasoning, validating actions, and observing multi-agent interactions to detect subtle betrayals or misalignment, recognizing that harm is often highly contextual.
John Dickerson, CEO of Mozilla AI, argued that open source is essential for security, providing necessary transparency, choice, and avoiding vendor lock-in. He teased an upcoming release of any-guardrail an open-source wrapper for guardrail libraries. This slots in nicely along standard interfaces like any-llm and any-agent.
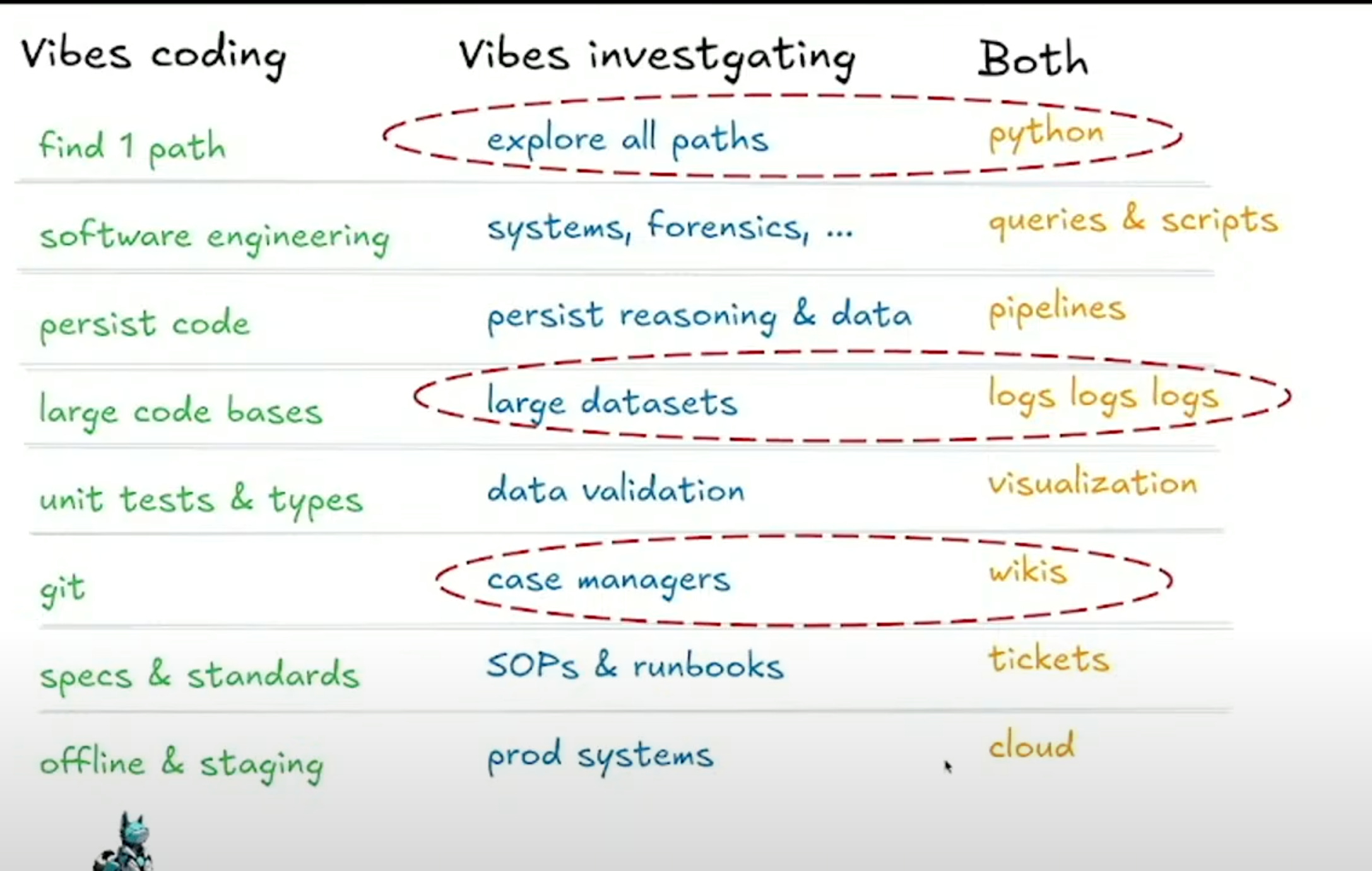
Vibes Investigating
Agentic AI is already proving to be a boon for defenders. Leo Meyerovich, CEO of Graphistry, talked about "Vibes Investigating"—using agentic AI to tackle the overwhelming scale of security data that leads to analyst burnout. Unlike a coding agent that seeks a single correct path, an investigative agent must "explore all paths" to ensure nothing is missed.
The results speak for themselves. Louie compressed over 20 hours of human analyst work in Splunk’s BOTS competition into one hour, auto-solving 73% of the challenges. It’s awesome to see the product’s evolution since I first heard about it at Graph the Planet at RSA two years ago.
Building towards secure (and reliable) trajectories
We are witnessing a fundamental shift from chatbots to autonomous systems. Yet, a dose of realism is warranted. Panelists during the Enterprise Agents session cited reliability and hallucination as the biggest blockers to enterprise adoption today. Agent reliability will likely improve through better underlying models and techniques like reinforcement learning from verifiable feedback by optimizing actions taken on objective success signals, not just subjective human preference.
As agents become more capable and widespread, securing them requires us to move beyond today's threat models. The path to secure agentic AI demands standardized evaluation, comprehensive oversight, and a commitment to open, security-first design. The conversations this week will determine how quickly we get there.
Thanks for sharing Matt; great insights here as we explore making agents secure, reliable, and auditable.